Prior to 1994, student registration at Newcastle University involved students being registered in a single place within the University, where they would present a form which had previously been filled in by the student and their department. After registration this information was then transferred to a computerised format. The University decided that the entire student registration process was to be computerised for the Autumn of 1994, with the admission and registration being carried out at the departments of the students. Such a system has a very high availability requirement: admissions tutors and secretaries must be able to access and create student records (particularly at the start of a new academic year when new students arrive). The Arjuna distributed system has been under development in the Department of Computing Science for many years. Arjuna's design aims are to provide tools to assist in the construction of fault-tolerant, highly available distributed applications using atomic actions (atomic transactions) and replication. Arjuna offers the right set of facilities for this application, and its deployemnt would enable the University to exploit the existing campus network and workstation clusters for providing transactional access to data; further, this data can be made highly available by replication over distinct workstations, thereby obviating the need for any specialised fault tolerant hardware. This paper discusses the design and implementation of the registration system that has successfully met the requirements and is in use since 1994.
In most British Universities, the process of registering all student as members of the institution is largely concentrated into a very short period of time. At the University of Newcastle, the registration period occupies a little over a week in October, at the start of the academic year. The purpose of the registration process is to determine which students will be taking courses within the University, and for the administration to keep its records up-to-date. From the students point of view, registration enables them to acquire the necessary authorised membership of the University, and for them to obtain their grant cheques. It is usually the case that students will register for particular courses, or modules, at the same time, and the information collected is used by members of the teaching staff to construct class lists, etc.
Prior to 1994, registration involved students being registered in a single place within the University, where they would present a form which had previously been filled in elsewhere by the student and their department. After registration this information was then transferred to a computerised format. In 1993, the University decided that the entire student registration process was to be computerised for the Autumn of 1994. The decision was therefore made to try to decentralise the operation so that the end users of the course data, the various University Departments, would have more control over the accuracy of the data entered. It was also expected that the delay before the final data could be delivered back to the departments would be considerably reduced.
The registration process is extremely important to the University and the students: the University cannot receive payment for teaching the students, and students cannot receive their grants or be taught until they have been registered. The computerised registration system was intended to tolerate machine and network failures. It was hoped that most human errors, such as incorrectly inputting data, would be detected by the system as they occurred, but it was expected that some "off-line" data manipulation would be necessary for errors which had not been forseen. Therefore, the success of any attempt to computerise this activity depends on the reliability, availability and integrity of the computer systems, both software and hardware, on which the registration programs are run. Because many of the University departments already had significant investments in computer hardware, it was decided that no specialised harware should be provided. Therefore, software fault-tolerance was to be used.
The Arjuna distributed system [ref] has been under development in the Computing Science Department at the University since 1986. The first public release of the system was made available in 1992, and since then the system has been used by a number of academic and commercial organisations. Arjuna's design aims are to provide a set of tools to assist in the construction of fault-tolerant, distributed applications using atomic actions (transactions) [ref] and replication to maintain availability and consistency. It was felt that a student registration system built using Arjuna would provide a test application which would exercise the Arjuna system much more rigorously than had hitherto been attempted, and would result in a registration system which exhibited the reliability and availability required.
The registration system been in use since October 1994, and during each five day registration period approximately 14,000 students are registered. This paper describes the design and implementation of the registration system and the experience gained.
Arjuna is an object-oriented programming system, implemented in C++ [], that provides a set of tools for the construction of fault-tolerant distributed applications. Objects obtain desired properties such as concurrency control and persistence by inheriting suitable base classes. Arjuna supports the computational model of nested atomic actions (nested atomic transactions) controlling operations on persistent (long-lived) objects. Atomic actions guarantee consistency in the presence of failures and concurrent users, and Arjuna objects can be replicated on distinct nodes in order to obtain high availability.
The object and atomic action model provides a natural framework for designing fault-tolerant systems with persistent objects. When not in use a persistent object is assumed to be held in a passive state in an object store (a stable object repository) and is activated on demand (i.e., when an invocation is made) by loading its state and methods from the persistent object store to the volatile store. Arjuna uniquely identifies each persistent object by an instance of a unique identifier (Uid).
Each Arjuna object is an instance of some class. The class defines the set of instance variables each object will contain and the methods that determine the behaviour of the object. The operations of an object have access to the instance variables and can thus modify the internal state of that object. Arjuna objects are responsible for their own state management and concurrency control, which is based upon multiple-readers single-writer locks.
All operation invocations may be controlled by the use of atomic actions which have the well known properties of serialisability, failure atomicity, and permanence of effect. Furthermore, atomic actions can be nested. A commit protocol is used during the termination of an outermost atomic action (top-level action) to ensure that either all the objects updated within the action have their new states recorded on stable storage (committed), or, if the atomic action aborts, no updates are recorded. Typical failures causing a computation to be aborted include node crashes and continued loss of messages caused by a network partition. It is assumed that, in the absence of failures and concurrency, the invocation of an operation produces consistent (class specific) state changes to the object. Atomic actions then ensure that only consistent state changes to objects take place despite concurrent access and any failures.
Distributed execution in Arjuna is based upon the client-server model: using the Rajdoot remote procedure call mechanism (RPC) [], a client invokes operations on remote objects which are held within server processes. Distribution transparency is achieved through a stub generation tool which provides client and server stub code which hides the distributed nature of the invocation. The client stub object is the proxy of the remote object in the client's address space; it has the same operations as the remote object, each of which is responsible for invoking the corresponding operation on the server stub object, which then calls the actual object [].
Arjuna does not assume that objects and servers are always running. Therefore, when a client first requests an operation on a remote object, it sends a message to a special daemon process called the manager, requesting the creation of a new server, which is then responsible for replying to the client. The server may not respond immediately, either because the manager is busy with other requests, or because the server has crashed. The only way the client can discover that the server is working is by receiving a reply to its request, but if no reply is forthcoming the client's response is to retry the request. Only when the client has failed to receive a reply on a number of occasions will it assume the server has failed. If the client sends a request and receives no reply, this may be because the manager is busy, in which case the client will eventually receive the response, or the server has crashed, so that no reply will ever be received. The length of time which the client should wait is therefore crucial to the performance of the system. If the time-out interval is too short, requests will be repeated unnecessarily, but if it is too long, the client might wait a long time before the system realises that the server has crashed.
In order to better distinguish between the case where the server has crashed and the machine is merely running slowly, Arjuna has a dedicated daemon process, the ping daemon, whose sole responsibility is to respond to "are you alive" messages. Whenever a client has not received a response to an RPC it "pings" the destination machine. If this call fails then the machine is assumed to have failed, otherwise the RPC retry is performed. Because of network congestion or an overloaded machine it is still possible for a client to fail to receive a reply to "ping" from an available machine and incorrectly assume the machine has crashed. However, the use of a ping daemon reduces the probability of an incorrect decision. Despite a successful response to the "ping" request, the RPC call could still fail, possibly because the manager process has crashed or is too busy to respond, but a failure of the whole server machine will be detected much earlier using this technique.
A persistent object can become unavailable due to failures such as a crash of the object server, or network partition preventing communications between clients and the server. The availability of an object can be increased by replicating it on several nodes. The default replication protocol in Arjuna is based upon single-copy passive replication: although the object's state is replicated on a number of nodes, only a single replica is activated, which regularly checkpoints its state to the object stores where the states are stored. This checkpointing occurs as a part of the commit processing of the application, so if the activated replica fails, the application must abort the affected atomic action. Restarting the action can result in a new replica being activated.
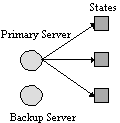
This is illustrated in Figure 1, where an object's state is replicated on three object stores. The server which is used to access the object is replicated twice; one of the servers is designated as the primary and the other is its backup. All clients send requests to the primary, which loads the state of the object from any one of the replicated object stores. If the state is modified it is written back to those stores when the top-level action commits. States which cannot be updated are excluded from subsequent invocations until they have been updated by a recovery mechanism. If the primary server fails then clients make use of the backup. As long as a single state and server replica are available, the object can be used.
Based upon the experiences of the previous registration process, it was anticipated that 100 workstations would be necessary for the purposes of the registration exercise. These workstations, which would be a mixture of PC-compatible machines and Apple Macintosh systems, would be distributed throughout the University departments and campus. For each of these two types of system, a user-friendly interface program (front-end) was written, which would display the equivalent of the original paper registration form. The student data would be retrieved from an information store, written using Arjuna. In the following sections we shall examine this architecture in more detail.
It is important that the student information is stored and manipulated in a manner which protects it from failures such as machine crashes. Furthermore, this information must be accessible from anywhere in the campus, and consistent despite concurrent accesses. Therefore, a distributed information store (the registration database) was built using the facilities provided by Arjuna. The database represents each student record as a separate persistent object, the StudentRecord, which is responsible for its own concurrency control, state management, and replication. This enables update operations on different student records (StudentRecord objects) to occur concurrently, improving the throughput of the system. Each StudentRecord object was manipulated within the scope of an atomic action, which was begun whenever a front-end system requested access to the student data; this registration action may modify the student record, or simply terminate without modifying the data, depending upon the front-end user's requirements.
Each StudentRecord has methods for storing and retrieving the student's information:
retrieveRecord: obtain the student data record from the database, acquiring a read lock in the process.
retrieveExclusiveRecord: obtain the student data record, acquiring a write (exclusive) lock.
storeRecord: store the student data in the database; if a record already exists then this operation fails.
replaceRecord: create/overwrite the student data in the database.
These methods are accessed through a server process; one server for each object.
To improve the availability of the database, it was decided to replicate each StudentRecord object, as described in Section 2. Because it is possible to replicate an object's methods (the server processes) and state independently we decided to replicate the object states on three machines dedicated to this purpose (HP710s), the object stores. The system could therefore tolerate the failure of two object store machines.
As previously described, the registration system was expected to cope with 100 simultaneous users. Because each StudentRecord is accessed through a separate server process this requires the ability to deal with 100 simultaneous processes. Therefore we allocated five machines (also HP710s) to evenly distribute this load. These machines were also used to replicate the StudentRecord servers: each StudentRecord object was allocated a primary server machine, with backup server machines in the event of failures. If a server machine failed, load was evenly redistributed across the remaining (backup) machines. To reduce the load in the event of multiple machine failures each primary had only two backups.
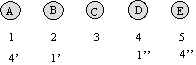
Figure 2 illustrates the server replication for 5 student numbers. Machine A is the primary server for student number 1, with the first backup on machine B, and the final backup on D. Similarly, for student number 4, the primary server machine is D, with primary and secondary backups A and E respectively.
Each student is identified within the University, and to the database system, by a unique student number. With a suitable hashing function, the student number was found to provide a uniform distribution of primary servers across the server machines. When a primary machine failure was detected, each client machine recomputes the location of the new primary server for each student object based upon the new number of available machines. This mapping of student number to server location was only performed upon each open request.
At the start of each registration day each front-end system is connected by a TCP connection to one of five HP710 UNIX systems. One process for each connected front-end is created on the UNIX system; this process is responsible for interpreting the messages from the front-end and translating them into corresponding operations on the registration database. This is the Arjuna client process, and typically existed for the day. In order to balance the load on these systems, each user was asked to connect to a particular client system. If that system was unavailable, then the user was asked to try a particular backup system from among the other machines.
The client processes, having received requests from the front-end systems, are then responsible for communicating with the Arjuna server process which represents the appropriate StudentRecord object. As described in Section 3.1, the location of each server process was determined by the student number. If this is a request to open a student's record, then the client process starts an atomic action within which all other front-end requests on this student will occur. The server process exists for the duration of the registration action.
Thus, the final configuration of machines and processes is as shown in figure 3, where the processes are represented as circles.
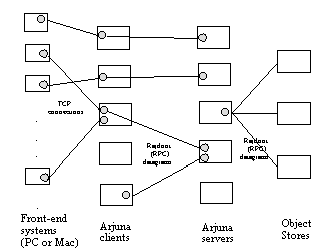
It was possible to use five machines for both client and server processes. Thus eight machines are employed in all, with up to 100 front-end systems.
Included with the front-ends were 2-5 swipe-stations, which were introduced in the second year of operation. Registration forms were modified to include a bar-code containing the student's registration number. This was used by the swipe-stations to quickly determine the status of a student. These stations were only used to read the student's data, and therefore no modification of the data occurred.
Having described the overall system architecture we shall now examine the operation of the registration system, showing how existing students were registered, new students were added to the system, and the data was examined.
Prior to the start of the registration period, the database was pre-loaded with data pertaining to existing students, and data from the national university admissions scheme, UCAS, who supply data concerning new students who are expected to arrive at the University. However, under some circumstances it was expected that a small number of new student records would have to be created during the registration process itself:
A student may, for some reason, have been admitted directly by the University. This can happen in the case of students admitted very late in the admissions process. Such students do not possess a student number, and have to be assigned a valid number before registration can occur.
There are also a number of students who, having formerly been students at the University, wish to return to take another course. It is the University's policy in these circumstances to give the student the same number as s/he used previously.
Thus, requests to create new records need to allow the user to supply the student number corresponding to the new record, or to allow the system to assign a student number.
Section 2 described how Arjuna identifies each persistent object by an instance of a Uid. However, the University allocated student number has a different structure to the Arjuna Uid. Therefore, part of the database, called the keymap, is also responsible for mapping from student numbers to Uids. This mapping is created during the initial configuration of the database, and uses the UNIX ndbm data base system [ref]. This mapping remains static during the registration period, and therefore each client machine has its own copy. The client is reponsible for mapping from the front-end supplied student number to the corresponding Arjuna Uid in order to complete the request. The handling of requests for new records may require new records to be created, with a corresponding mapping of new Uid to student number. This will be described later.
The front-end workstations run a program which presents the user with a form to be completed on behalf of a student. The initial data for this form is loaded from the registration database, if such data already exists within the system, or a completely new blank form is presented in the case of students not previously known to the system. The form consists of a variety of fields, some of which are editable as pure text, some of which are filled from menus, and some of which are provided purely for information and are not alterable by the user.
A registration transaction consists of the following operations:
(i) either opening (asking to retrieve) the record, or creating a new record.
(ii) displaying the record on the screen of the front-end system.
(iii) either closing it unmodified, or storing the record in the database.
The entire transaction occurs with an atomic action. The actual operations will be described in more detail later but we present an overview here:
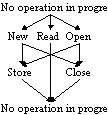
Open: retrieves an existing record from the database. This operation is used when the record may be modified by the front-end system, and therefore a write-lock is obtained on the database object.
New: for students not already registered in the database this operation allows a new record to be created and modified before being stored.
Close: terminates the atomic action without modifying the record in the database.
Store: stores the record in the database, and terminates the atomic action.
Read: retrieves an existing record from the database, in read-only mode. This operation is typically used by the swipe-stations, and does not allow modification of the record. Therefore, the Arjuna client immediately invokes a Close request upon receiving the student data.
In order to start the processing of a record, the user is required to enter the student number, which is the user's method of keying into the student record database. A registration transaction is started upon receipt by an Arjuna client of an Open or New request from a front-end; the client starts an atomic action and the object corresponding to that record is activated. This involves the creation of a server process, which is then requested to retrieve the object from the object store. The architecture described above clearly implies that there is one instance of a client for each active front end. Thus, there should be at most one such active object extant for each client. Although the workstation programs were intended to avoid the possibility of multiple Open calls being made, it was decided to insure against erroneous behaviour on the part of the front-end by implementing the client program as a simple finite state machine. Thus, following an Open request, further Open requests are regarded as inadmissible until a subsequent Close or Store operation has been performed. Similarly, Close and Store operations are regarded as invalid unless there has previously been a successful Open request. This is illustrated in Figure 3.
The Arjuna student record object is responsible for ensuring that the record is locked at the start of a transaction, and the atomic action system automatically releases the lock when the action completes (either successfully, or as a result of some failure condition). As stated previously, Read operations obtain read locks on the student object, whereas Open and New operations obtain write locks.
In the following sections we shall examine in detail the front-end operations, and how they interact with the StudentRecord objects in terms of the protocol described previously and the operations it provides.
The Open operation is used to retrieve a record from the database given the student number. This operation assumes that the record exists, and one of the failure messages that may be returned indicates that there is no record corresponding to the given student number. The Open operation first has to interrogate the keymap to map the student number into a corresponding Arjuna Uid. If an Arjuna Uid is successfully located, an atomic action is started, and a retrieveExclusiveRecord call is made to the appropriate object (server), chosen according to the supplied student number. The lock on the record is acquired at this point, and is held until the atomic action either commits or aborts.
The retrieveExclusiveRecord call will either succeed, in which case the record is delivered to the front-end, or it will fail, causing an error message to be returned to the front-end and the atomic action to abort. The reasons why this call may fail are that the record does not exist, or the record is locked. If retrieveExclusiveRecord indicates that the record is locked, then this information is relayed directly back to the user via an appropriate message; the user then has the option of retrying, or attempting some other activity. The remaining failure is basically a "no reply". This is interpreted by the client as a failure of the server process. If this occurs, then the client attempts to access the record using one of the backup servers, as described previously.
The server process created in response to the retrieveExclusiveRecord call remains in existence until the client informs the server that it is no longer required. This will happen either because the retrieveExclusiveRecord call itself fails, or because the front-end user finishes the transaction through the Store or Close operations. The life of the server, the object, and the atomic action is precisely the duration of a registration transaction. Thus, the Open command will typically create an instance of the object, but does not necessarily destroy it.
The Read operation is similar to Open, but invokes the retrieveRecord operation on the object. Because this obtains the student record data for read-only operations, such as required by the swipe-stations, the client automatically issues a Close request. This helps to reduce the time for which the record is locked, which could prevent other users from manipulating the data. This is the only operation which the front-end can issue which encapsulates an entire registration transaction, i.e., when the student data is finally displayed the registration atomic action, student record object, and server have all been terminated.
The Store operation is used to commit the atomic action and transfer the data, possibly modified by the user, into the database. The Store message generates a replaceRecord call to the server, which may fail because the server has crashed. This is a potentially more serious situation than if the server crashes before a retrieveExclusiveRecord call is made, since this represents a failure while an atomic action is in progress. All modifications made between retrieval and the attempt to save the record will be lost, but the atomic action mechanism will ensure that the original state of the record is preserved. If the Store fails, an appropriate message will be displayed at the front-end and the user has the option to restart the atomic action.
The Close operation is used simply to end the registration atomic action. It is used in the situation where a user has retrieved a record, has no further use for it, but does not wish to modify it. The Open operation will have started a new atomic action, and have caused a server process to be created. The Close terminates the atomic action (causes it to abort) and also causes the server process to terminate. The Close operation cannot fail even if the server crashes; a failed server will simply impact on performance since aborting the action includes includes sending a message to the server asking it to terminate.
Some students may appear at registration having no record in the database. There are two possible reasons for this, and hence two variants of the New operation:
(i) the student is returning unexpectedly for another year, and already has a valid student number given in a previous year.
(ii) the student is new to the University and does not have a student number. Therefore, the front-end number field is set to zero, and the system allocates a new student number from a pool of "spare" numbers.
In case (ii), the pool of numbers is known before the registration begins, and blank records are pre-created and registered with the system; the mapping from Uid to student number is also known and written in the keymap database. In order to ensure that simultaneous New requests obtain different student numbers, the system uses another (replicated) Arjuna object: an index object, which indicates the next available student number in the free pool. This object is concurrency controlled and accessed within an atomic action, which guarantees that each request obtains a different student number.
However, in case (i) a new Arjuna object representing the student record has to be created and stored in the database, and the appropriate mapping from student number to Arjuna Uid stored in an accessible place. The creation of new keymap entries poses a problem of synchronising the updates to the individual copies of the keymap database on the various client machines. It was decided that the problems associated with the New operation could be solved by administrative techniques, and by accepting a single point of failure for this minor part of the operation. An alternative ndbm database called newkeymap was created in the shared file store, available to each Arjuna client system via NFS. This database contained the mappings between new database object Uids and their corresponding student numbers. It was read/write accessible to users, and was protected from simultaneous conflicting operations via a lock.
Any Open request must clearly be able to observe changes made to the database as a whole, and therefore it will have to search both the newkeymap and the keymap databases. If the shared file service becomes unavailable, no new student records can be created, and neither is it possible to access those new student records which have already been created. It would be possible to minimise this difficulty by merging the newkeymap and new keymap at times when the system is quiescent.
Given the new (or front-end supplied) student number, a corresponding database object is created with a blank record, using the replaceRecord operation. The front-end user can then proceed to input the student's information. In order to ensure that there would never be any conflict over multiple accesses to newkeymap, and therefore to the new number pool, it was also decided that the New command should be disabled on each front-end system except one, which was under the direct control of the Registrar's staff. This machine had several backups.
During the development of the front-end programs, tests were done to ensure that the front-end software performed satisfactorily. However, the timetable for the whole operation meant that it was impractical to mount a realistic test using the intended front-end systems themselves, involving as it would a human operator for each such station. However, it proved relatively straightforward to construct a program to run on a number of Unix workstations around the campus, which simulated the basic behaviour of the front-end systems as seen by the registration database. Wach simulated front-end system would retrieve a random record, wait a short period of time to simulate the action of entering data, and then return the record to the system, possibly having modified it.
It had been estimated that over the registration period, the system would be available for some 30 hours. In this time, it was expected that of the order of 10,000 students would be registered. In some cases, the student record would need to be accessed more than once, so that it was estimated that approximately 15,000 transactions would take place. We therefore anticipated that the expected load would be of the order of 500 transactions per hour, or a little over six per workstation per hour. This however would be the average load, but it was felt that it would be more realistic to attempt to simulate the peak loading, which was estimated as follows: the human operator would be required to enter data for each student in turn; the changes to be made to each record would range from trivial to re-entering the whole record. In fact, in the case of students for whom no record was pre-loaded, it would be necessary for the whole of the students data to be entered from the workstation. It was therefore estimated that the time between retrieval and storing of the record would be between 30 seconds and 5 minutes.
A program was written which began by making a TCP connection to one of the Arjuna client machines. It then selected a student number at random from the keymap data base, retrieved the corresponding record, waited a random period of time, and then returned the record with a request either to store or simply to close the record. This final choice was also made at random. After performing the simulated transaction a fixed number of times, the program closed the TCP connection and terminated. The program recorded each transaction as it was made, the (random) time waited, the total time taken and the number of errors observed.
The object of this test was to discover at what point the system would become overloaded, with a view to "fine-tuning" the system. At the level of the Arjuna servers, it was possible to alter a time-out/retry within the RPC mechanism (i.e., between client and server) to achieve the optimal performance, and also to tune the ping daemon described earlier.
The front-end simulation therefore arranged for the record to be retrieved, a random interval of time uniformly distributed in the range 30 to 300 seconds was allowed to elapse, and the record was then returned to the system. The variable parameters of the system were:
the range of values for the time between retrieving and storing the record.
the probability that the returned record would have been modified.
the number of transactions to be performed by each run of the program.
The Arjuna ping daemon was described in Section 2.1. The failure of a machine is suspected whenever a ping daemon fails to respond to an "are you alive" message. In order to reduce the probability of incorrect failure suspicion due to network and machine congestion it was important to tune the timeout and retry values which the ping daemon used. The RPC has its own timeout and retry values, and the ping daemon is only used when an RPC timeout occurs. It was obviously important to tune these values as well. Therefore, by running the tests at greater than expected maximum load it was possible to tune these values to reduce the possibility of incorrect failure suspicion.
The longest run of the test program carried out a total of 1000 simulated transactions, which took approximately 2 hours to complete. With 10 such processes running, this represented 10000 transactions in about 2 hours, or 5000 transactions per hour. This was far in excess of the expected average load during live operation, and approximately twice the expected maximum transaction rate. From these results, we tuned Arjuna to detect a crashed machine in 10 seconds. Because the simulated load was greater than that expected during registration, we were confident that we could differentiate between overloaded and crashed machines during registration.
The live experience was acquired by observing, and to some extent participating in, the operation of the system during actual registration. Many of the problems that arose during this period were unrelated to the technical aspects of the system. Such problems were: incorrect operation of the system by its operators, including attempting to repeat operations because the response was not perceived to be satisfactory, failure to install the latest version of the software on the workstations, and similar problems. In fact overall the system performed extremely well, with good performance even in the presence of failures.
There was one major difficulty that arose during the first year of operation which caused the system to be shut down prematurely (about half an hour earlier than scheduled). This occurred at the time when, and because, the system was heavily loaded. The original figures for the number of registration users and hence the expected rate of transactions were exceeded by over 50%. Because the system had not been tuned for this configuration, server processes began to incorrectly suspect failures of object store machines. Because the failure suspection depends upon timeout values and the load on the object store machine, it was possible for different servers to suspect different object store machine failures. This virtual partitioning meant that some replica states diverged instead of all having the same states, and therefore it was possible for different users to see inconsistent states. Using timestamps associated with the object states it was possible to reconcile these inconsistencies, and the system was re-tuned to accommodate the extra load.
Although no hardware failures occurred during the first year, in the second year the registration system had to cope with two machine failures. The machines which we were using for registration were shared resources, available for use by other members of the University. One of the Arjuna client machines had a faulty disk which caused the machine to crash when accessed over NFS. This occurred twice during the registration period when other users of the machine were running non-registration specific applications which accessed the NFS mounted disk.
The following graphs are based upon the statistics gathered from the 1995-1996 registration period. Graph 1 shows the total number of transactions (Open/Save, Read/Close, New/Save) performed during each hour of the registration operation. The registration system was active for 10 days: the first 5 days were the main period when students presented themselves for registration, whereas the last 5 days were used more for administration purposes. Each day is represented by two peaks, representing the main morning and afternoon sessions, with the minimum occurring when students went to lunch.
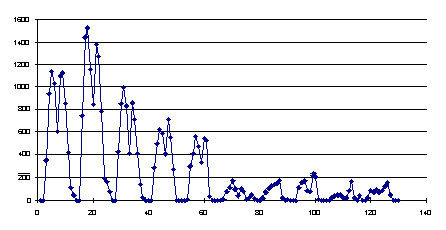
As can be seen from the graph, the main period occurred on the second day, when approximately 10,000 transactions occurred, with an average rate of 2500 transactions per hour. The large number of transactions, and the high transaction rate can be attributed to the swipe stations, which only performed Read/Close operations.
Graph 1 showed all transactions which occurred during a given registration day. Graph 2 shows the number of New/Save operations which occurred. Most new students were registered during the first two days, with approximately 400 being registered in that period, with an average rate of 25 transactions per hour.
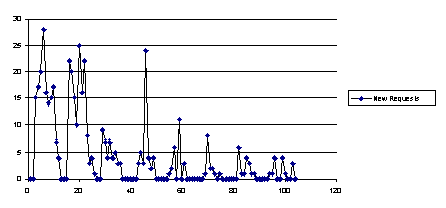
The workstations, and particularly the Macintosh versions, took some time to process a record once it had been retrieved. This was because the record itself contained much of its information in coded form, and it was thought preferable for the user to be presented with somewhat fuller information. The transformation from coded form to "usable" form was carried out at the workstation. Typically, the Arjuna database would respond to an Open request in less than 1 second, and the front-end processing would take approximately 5 seconds. Therefore, the record would be available to the user within 7 seconds of making the request.
The Arjuna system was used in this exercise in an attempt to provide high reliability and availability in case of possible failure of certain components. When failures did occur, the use of atomic actions and replication guaranteed consistency and forward progress. The system performed well even at maximum load, and the occurrence of failures imposed a minimum overhead, such that most users did not realise anything had happened. In the context of the ultimate purpose of the exercise, namely the completion of the registration process, the outcome was exactly what we could have wished for. The University has committed to continue to use the registration system, and some considerable effort has gone into making the system manageable by non-Arjuna experts.
Acknowledgments
References
[11] S. K. Shrivastava, G. N. Dixon, and G. D. Parrington, "An Overview of Arjuna: A Programming System for Reliable Distributed Computing," IEEE Software, Vol. 8, No. 1, pp. 63-73, January 1991.
[2] F. Panzieri and S. K. Shrivastava, "Rajdoot: A Remote Procedure Call Mechanism Supporting Orphan Detection and Killing", IEEE Transactions on Software Engineering, Vol. SE-14, No. 1, January 1988.
[3] G. D. Parrington et al, "The Design and Implementation of Arjuna", USENIX Computing Systems Journal, Vol. 8., No. 3, Summer 1995, pp. 253-306.
[4] M. C. Little and S.K. Shrivastava, "Replicated K-Resilient Objects in Arjuna", in Proceedings of 1st IEEE Workshop on the Management of Replicated Data, Houston, November 1990, pp. 53-58.
[5] M. C. Little, "Object Replication in a Distributed System", PhD Thesis, University of Newcastle upon Tyne, September 1991. (ftp://arjuna.ncl.ac.uk/pub/Arjuna/Docs/Theses/TR-376-9-91_EuropeA4.tar.Z)
[6] M. C. Little, D. McCue and S. K. Shrivastava, "Maintaining information about persistent replicated objects in a distributed system", Proceedings of ICDCS-13, Pittsburgh, May 1993, pp. 491-498.
[7] M. C. Little and S. K. Shrivastava, "Object Replication in Arjuna", BROADCAST Project Technical Report No. 50, October 1994. (ftp://arjuna.ncl.ac.uk/pub/Arjuna/Docs/Papers/Object_Replication_in_Arjuna.ps.Z)
[8] D. B. Lomet, "Process structure, synchronisation and recovery using atomic actions", in Proceedings of ACM Conference on Language Design for Reliable Software, SIGPLAN Notices, Vol. 12, No. 3, March 1977.
[9] S. K. Shrivastava, "Lessons learned from building and using the Arjuna distributed programming system," Int. Workshop on Distributed Computing Systems: Theory meets Practice, Dagsthul, September 1994, LNCS 938, Springer-Verlag, July 1995 (also: Broadcast Project Deliverable Report, July 1995, http://arjuna.newcastle.c.uk/arjuna/papers/lessons-from-arjuna.ps).
[10] L. E. Buzato and A. Calsavara, "Stabilis: A Case Study in Writing Fault-Tolerant Distributed Applications Using Persistent Objects," Proceedings of the Fifth Int. Workshop on Persistent Objects, San Miniato, Italy, September 1-4, 1992.
[11] S. K. Shrivastava and D. McCue, "Structuring Fault-tolerant Object Systems for Modularity in a Distributed Environment," IEEE Trans. on Parallel and Distributed Systems, Vol. 5, No. 4, pp. 421-432, April 1994.
[12] G. D. Parrington, "Reliable Distributed Programming in C++: The Arjuna Approach," Second Usenix C++ Conference, pp. 37-50, San Fransisco, April 1990.
[13] G. D. Parrington, "Programming Distributed Applications Transparently in C++: Myth or Reality?," Proceedings of the OpenForum 92 Technical Conference, pp. 205-218, Utrecht, November 1992.
[14] G. D. Parrington, "A Stub Generation System for C++"
Computing Systems, Vol. 8, No. 2, to be published, 1995. (Earlier
version available as BROADCAST Project deliverable report, November
1994; http://www.newcastle.research.ec.org/broadcast/trs/papers/67.ps).