Regard the various separate Unix systems as being (large) leaves on a unique global Unix system naming tree (a copy of which would be held in each system), but also provide means of naming by which each Unix system can name the others directly. This naming scheme then would be supported by physical interconnections, such as local area networks, of possibly quite different topology, and remote procedure call services which would be involved automatically when inter-Unix information transfer was implied by a command-level or program- level statement.
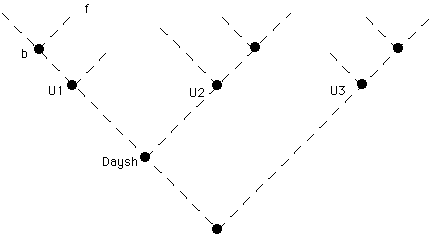
The figure below shows three interconnected Unix systems, and represents the overall tree formed from their directory hierarchies and the system naming tree. Two systems are (with respect to names and probably, but not necessarily, physical links) closely connected, the third being a more distant system. The curved lines represent additional links (called 'r-links') which serve as path name abbreviations, and so allow direct inter-system naming. Just a few such r-links are shown but in a small collection of Unix systems, each system might have r-links to all the others. (See Figure 1)
Assume that within each Unix system, '/' is left at its normal position at (what appears to be) the root of the (local) directory tree. Then within Ul, f is known as /b/f. From U2 it can be known either as /../U1/b/f or (via the r-link) as /U1/b/f. From U3 it is known just as /../../Daysh/Ul/b/f, though a suitable r-link could also abbreviate this to /Ul/b/f.
The tree form of the inter-Unix naming structure provides a convenient means of uniquely identifying all files, etc., which is indefinitely expansible. The system of r-links enables details of this naming structure to be hidden, much as can be done within a single Unix using links to files. The r-links are special, in that they only exist in root directories, and point to other roots (just as ordinary links can only point to files rather than directories). As mentioned above they are to be thought of as abbreviations, rather than as paths which might be followed in tree-searching algorithms and so cause potential cycles in the overall directory structure. (An actual implementation of this scheme might use the normal Unix directory mechanism for the whole tree, and incorporate some new means of identifying the root node.)
The act of interconnecting two or more Unix systems in this way (which we will call 'syslinking') involves ensuring that each system has a copy (or at least access to a copy) of the system naming tree, and obviously requires that any changes to the tree be made to all copies atomically. (Completion of the set of required r-links need not be atomic.) The present assumption is that such syslinking would be done quite infrequently, and that the fact of the intended existence, if not the full functionality, of the syslinking would survive during accidental disconnections of systems, just as international telephone directories continue to exist even when transatlantic telephone links are not available. Thus one can conceive of quite crude means of performing syslinking atomically - a super-super-user perhaps! If, on the other hand, syslinking were thought of as a (frequently used) means of binding together more closely systems that already had a means of interconnection (e.g. network message passing), then one can imagine it being done automatically on command, using some sort of two-phase commit-type protocol to prevent cycles from forming.
With this syslinking scheme, it would be possible to write shell commands which referred to programs and files on various different Unix systems, with the same syntax and semantics as if just a single conventional Unix system was involved. Thus given appropriate file structures on various systems,
/Ul/sort /U2/data I /U3/lpr
could have been entered into system U4, and would have caused U2's data to be sorted using Ul's sort program and spooled onto U3's printer. If however the command had been entered on Ul, for example, the program could have been identified just as sort.
Two other separate issues are (i) the choice of which system given program
blocks are executed and data blocks are held on, and (ii) whether or not
actual parallel processing occurs after a process has forked. Processor
allocation for instance could simply be decided on by default (e.g. on the
system on which the original command was given, or where the program was
normally stored), could be controlled by the user (e.g. using a command
'remote The assumption therefore is that when a program has been loaded and is
running its accesses to objects that belong to another system can be
identified as such and performed using remote procedure calls to agent
processes on that system. It would not be the intention to try and perform
this identification beforehand, for example in the 'shell'. Indeed it
cannot be in general, given for example the fact that Unix allows file
names to be generated dynamically. In fact it would seem that the shell
would not need changing, and that, apart from the addition of remote
procedure call software, there would be comparatively few modifications to
be made to the system (though these would be rather deep inside the Unix
kernel). In effect the modifications insert a virtualising layer between
the kernel and its possibly remote objects, which maintains mapping tables
(set up by the syslinking operation) for these objects. The mappings can be
described in terms of file directory paths (e.g. b/f is mapped into
/Ul/b/f), but in fact will have to be given in terms of the object naming
convention(s) actually used deep inside the kernel. (These mapping tables
will contain (or point to) details of the actual physical lines between
systems.)
It is assumed that a user would sign on to a particular Unix system in the
usual way, and that activities that he caused in other systems would be
carried out for him by agent processes (which would need to have
appropriate capabilities for, e.g. file access, on his behalf). There would
be no requirementfor him to sign on explicitly to such other systems -
indeed special measures would have to be taken if it was wished to arrange
that he could be recognised as one and the same user by the multiple-Unix
system as a whole, no matter which specific Unix system he signed on to.
(This is a direct and appropriate consequence of regarding internal user
i.d.'s as mappable, i.e. possibly remote, objects.)
Some issues to be resolved: What other objects have to be mapped, being
possibly remote? Should remote procedure call facilities also be made
explicitly available, if so in what form? Should one be able to change the
current directory to being on a distant Unix, or down into the system
naming tree? Are the Unix file protection mechanisms sufficient to cope
with simultaneous attempts by two processors to modify the same file
directory hierarchy, providing one wishes to allow this? What problems are
there with buffering of file directories? Can one support Unix-style lines
between a directory on one Unix system and a file on another system (which
furthermore could withstand the directory rebuilding that sometimes has to
be done after a disc fault)? Is it satisfactory to rely on just one (local)
sign-on to enable access to a whole network of Unixes?
This proposal can be seen as resting on two assumptions - that one can deal
with naming in a multi-computer system with cavalier disregard for many
other issues, and that accesses to remote objects can be trapped and
handled by a hidden remote procedure calling mechanism.
However, in retrospect, our proposed solution seems so simple and obvious
that it surely cannot be novel, except perhaps with respect to Unix - is it?
... you have nothing to lose but your roots!
4. CONCLUSIONS
5. POSTSCRIPT (to the subtitle)
Contents Page - 40 years of Computing at Newcastle / Chapter (?) - Distributed Systems
Naming In A Set Of Linked Hierarchical Systems or Unixes of the World, Unite! , 27 June 1997
{kind=link}