Transport services are designed in order to provide fully reliable communication between processes exchanging data (messages) over unreliable media - they are particularly suitable for packet switching networks which are liable to damage, lose or duplicate packets. The implementation of a 'transport layer' tends to be quite expensive in terms of resources needed since a significant amount of state information needs to be maintained about the data transfer in progress. The initialisation and maintenance of this state information is required to support the abstraction of a 'connection' between processes. To reliably establish, maintain and terminate a connection is rather complex and a significantly large number of messages are needed just for connection purposes. (As a matter of interest, the so called Byte Stream Protocol (BSP) software for the Cambridge Ring can be regarded as supporting a transport service.)
On the other hand, a datagram service provides the facility of the transmission of a finite size block of data (a message known as a datagram) from an origin address to a destination address. In its simplest form, the datagram service does not provide any means of flow control or end to end acknowledgements; the datagram is simply delivered on a 'best effort' basis. If any of the features of the transport service are required, then the user must implement them specifically using the datagram service.
At a superficial level, it would seem that a good way to construct a reliable RPC would be to start with a reliable message service - the transport service. However we reject this viewpoint and adopt the datagram service as the more desirable alternative. The argument for this decision goes as follows. To start with it must be remembered that in the distributed system we have in mind, the users are not given the abstraction of sending or receiving messages; rather only a very specific piece of software - that needed to implement RPC - is the sole user of messages. As such the full generality of the transport service is simply not needed. The provision of the transport service entails a reduction of at least half of the available communication bandwidth (this is because of the overheads of connection management and the need for end to end acknowledgement). We may be able to utilise this bandwidth more effectively by reducing the need for connection management and acknowledgements as much as possible. This is indeed feasible in our particular case since the underlying hardware - the Cambridge Ring - provides a very reliable means of data transmission. So, a fairly reliable datagram service (whereby every datagram is delivered with a high degree of probability to its destination address) can certainly be built on top (in reality this would be a Basic Block Protocol with minor modifications). Any additional facilities needed are then specifically implemented making the implementation of the RPC a bit more complex but highly efficient.
(i) transmit-packet (destination, pkt, var status) where the acknowledgement is encoded as
status = (OK, unselected, busy, ignored, transmission-error)
The meaning of 'status' is as follows:
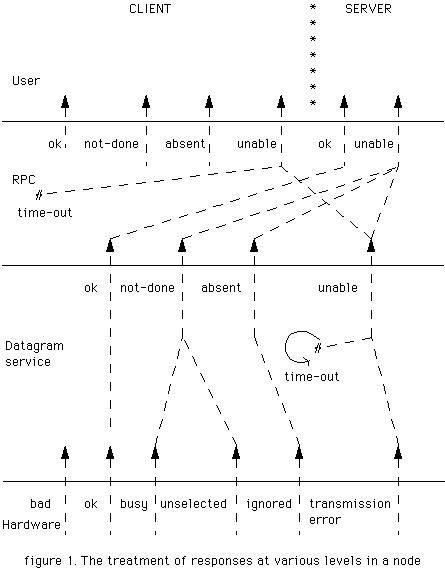
status = OK: The destination station has received the packet.
status = unselected: The packet was not accepted by the destination station because that station is currently 'listening' to some other source station.
station = busy: The packet was not accepted by the destination station because that station is currently deaf (not listening to anyone). Note that either of the above two status conditions implies that the destination station is most likely to become available shortly.
status = ignored: The packet was not accepted because the destination station is not on-line. This indication can be taken to mean that there is little chance of packets being accepted by that station for a while.
status = transmission error: The packet got corrupted somewhere during its passage through the Ring. This is the only case where the response of the destination station is not known.
It is worth mentioning here that the transmit primitive does not have a time-out response associated with it. As a consequence, the execution of this primitive will not return if the packet is not acknowledged due to a fault in the Ring hardware.
(ii) receive-packet ( var source; var pkt; var status) where,
status = (OK, bad)
The receive primitive allows for the reception of packets from either any source station on the Ring or from a specific source (a special operation is provided by the Ring for setting up a station in either of the modes). In either case, 'source' will contain the identity of the sender with 'pkt' containing the received packet. This packet is either good (status=OK) or corrupted (status=bad) indicating that a parity error has been detected. A curious aspect of the Ring is that the sender of the packet does not get 'bad packet received by the destination' response, rather it only gets the 'OK' response (this does not matter all that much in reality as the probability of a packet getting corrupted is really very low).
We shall assume that the Ring hardware either performs exactly as stated here or it simply does not work (in which case a "send" or "receive" operation does not terminate). If this assumption were realistic (which is what we are hoping) then the design to follow has some very nice reliability properties. Unpredictable hardware behaviour is likely to result in the same at the RPC/user interface to the extent that guaranteed behaviour can not be promised.
The datagram service will provide its user (a process) with the ability of (i) sending a block of data to a named destination process; and (ii) receiving a block of data from a specific or any process. We shall ignore here the fine details of how this may be implemented using the Ring operations described earlier; only the properties of the datagram service primitives will be described:
(i) send msg (destination; message; var status)
where,
status = (OK, absent, not-done, unable)
The message is broken into packets and transmitted to the home station of the destination process. If all these packets are accepted by the station then 'status=OK' will ho]d. Note that this only means that the message has reached the station, and not that it has been accepted by the destination process. If a packet is not accepted (possibly even after a few retries) by the station (packet level response is 'unselected' or 'busy') then 'status=not-done' will hold. A packet level response of 'ignored' is translated as 'status=absent' indicating that the destination process is just not available. The last two responses indicate that the message was not delivered. A time-out mechanism will be needed to cope with Ring malfunctions during the transmission of a message. The 'unable' status holds either if the time out expires or if a packet level 'transmission-error' response is obtained. The 'unable' response indicates inability of the datagram layer to deliver a message properly (the message may or may not have reached the destination).
(ii) receive_msg ( src, var msg)
The above primitive is to receive a message from a specified 'src' process. This primitive is implemented by repeatedly making use of the receive-packet(...) primitive. A time-out mechanism will be needed to detect an incomplete message transmission, Ring failures etc. In any case, unsatisfactory messages (these include messages containing bad packets) are simply rejected; so receive msg(...) only delivers a good message (if any). As a final implementation note, it is interesting to observe that often it is possible to inform the sender of the message that the receiver station has received a bad message. If a bad packet is received in the middle of a message transmission then the receiver station can make itself 'deaf' for a while so that the sender will get 'busy' responses in subsequent packet transmissions.
The receive msg(...) primitive can also be used for receiving messages from any source by simply specifying 'src' parameter as 'any'.
remote call (server, service, var result, var status, time-out)
where
status = (OK, not-done, absent, unable)
The meaning of the call under various responses is given below: status = OK: The service specified has been performed (exactly once) by the server and the answers are encoded in 'result'. status = not-done: The server has not performed the service because it is currently busy (so the client can certainly reissue the call in the hope of getting an 'OK' response). status = absent: The server is not available (so it is pointless for the client to retry). status = unable: The parameter 'result' does not contain the answers; whether the server performed the service is not known. The action of the client under this situation is application dependent; if the service required has the idempotency property then the client can retry without any harm, otherwise backward recovery must be invoked (how this is achieved is not relevant here). Note that we have pushed the decision of the invocation of backward recovery to the client rather than handling it at the RPC level - this is for the obvious efficiency reasons.
We believe that these responses are meaningful, simply understood and quite adequate for robust programming. We shall show next that it is possible to design RPC with the above properties based on our datagram service despite numerous fault manifestations in the distributed system (including node crashes). A skeleton program showing only the essential details of the RPC implementation is shown below; it should be self-explanatory. The following three assumptions will be made in the ensuing discussion: (i) some means exists for a receiver process to reject unwanted (i.e. spurious, duplicated) messages; the next section contains a proposal for achieving this end; (ii) node crashes amount to that station being not on line; and (iii) the work performed by a server is atomic - this means that we totally avoid the problems of handling orphans (this is a rather subtle point, remember B. Lampson's talk?). We now consider the treatment of exceptions during message handling.
| CLIENT | SERVER | |
|---|---|---|
| remote-call(...) corresponds | cycle | |
| to the following code: | --- | |
| --- | repeat "get work" | |
| send_msg( ); | --> | receive_msg(any,...) |
| "send service request" | until msg = valid; | |
| --- | --- | |
| --- | "perform work" | |
| set(time-out) | --- | |
| repeat | "send result" | |
| receive msg( ); | <-- | send msg( ) |
| until msg=valid; | ||
| --- | --- | |
| end |
(a) The client sends a service request: Recall that a send msg(...) can return the response 'OK', 'absent', 'not done' or 'unable'. If the response is 'OK' the control goes to the "set time-out" statement. If the response is 'absent' then the execution of remote call(...) terminates with 'status=absent'. If the response is 'not-done' then the message is re-sent. If after a few retries the same response is obtained then the execution of remote call(...) terminates with 'status=not-done'. A few retries can also be made if the send msg(...) results in an 'unable' response. If this response still holds then the execution of remote-call(...) terminates with 'status=unable'. Note that it is all right to send a message repeatedly. The server is in a position to discard any duplicates.
(b) The client waits for a message: The client prepares to wait for a response from the server. A time-out is set to stop the client from waiting for ever; the maximum duration of the waiting is as specified in the last parameter of the remote call(...). All the unwanted messages are discarded. A client may get such messages for example as a result of the actions performed by that node before it crashed and came up again. If a valid message is received then the execution of remote call(...) terminates with 'status=OK' and 'result' containing the answer. If the time-out expires then the execution of the remote call(...) terminates with 'status=unable'. Note that 'unable' response can be obtained for several reasons: server did not receive the message, server node crashed, server's message not received because of a Ring fault, etc.
(c) Server waits for a service request: Any spurious, in particular duplicated, messages are rejected. This guarantees that despite the possibility of repeated requests being sent by a client, only one service execution will take place.
(d) Server sends the reply: If the execution of send results in 'OK' response then the server is ready for the next request - it goes to the beginning of its cycle. Note that it is not guaranteed that the client will receive the reply. If the client does not receive the reply then it might explicitly invoke backward recovery. Such problems can be adequately handled within the framework of atomic actions and two phase commit protocols. If the 'send' operation gives rise to the 'absent' response then 'unable' is signalled to the server who can take any recovery actions. If the 'send' operation gives rise to either a 'not-done' or an 'unable' response then the message can be re-sent a few times before accepting defeat by signalling 'unable' to the server.
It is essential to separate those actions of the server that are not relevant at the 'RPC level'. We conclude that the level concerned with RPC implementation provides three operations: (i) remote call(...) - this is the client half of the program with the semantics discussed earlier; (ii) get work( ) - this corresponds to the repeat loop code of the server; and (iii) send result( , status) - this corresponds to the code concerned with sendingof the results, with status=(OK, unable), where the 'absent' response of send msg(...) and also the repeated occurrence of 'not-done' or 'unable' responses are all mapped onto 'unable' response of send-result. The 'unable' response indicates the inability of the RPC layer to deliver the result to the client (he may or may not have received the result). Thus, the recovery actions of the server are not made a part of the RCP level.
It should be noted that if fault manifestations are rare occurrences and messages are delivered with a high probability then almost always, only two messages are required for RPC (there are no hidden overheads). This is not possible if the transport service is used for message passing (we think that at least eight messages will be needed).
Finally, the treatment of various normal and abnormal responses is summarised in a pictorial form (See Figure 1)
(a) SNs are unique over a given client-server interaction: this would be the approach implicitly taken by a transport level supported RPC. This is a fairly complex approach needing a large amount of state information that has to survive crashes.
(b) SNs are unique over node to node interactions: Rather than maintaining state information on a process to process basis, it is possible to maintain information on a node to node basis; this kind of approach appears to have been adopted in the Xerox implementation. Clearly, it is more efficient than (a) above. However, the range of SN required is large (say 30/40 bits).
(c) SNs are unique over the entire system: We believe that this approach is about as complex as (b); most of the ingenuity is needed in the generation of unique SNs and hardly any crash-proof state information needs to be maintained at the RPC level. Assuming SNs are unique, a receiver need only maintain 'the last largest SN received' in a crash-proof storage. Further, all the retry messages are sent by a sender with the same SN as the original message. It is easy to see now that at the RPC level we have the property assumed in the previous section (that of rejecting unwanted messages).
There are two ways of generating system wide unique SNs: (i) the circulating token method of LeLann, and (ii) the losely synchronised clock approach of Lamport (as, say, used in SDD-l system). Our current favourite is the second approach. We shall not discuss the details here except to say that message overheads are minimal - every few minutes (10-15 min.) it is necessary for a node to send a message to others telling its current clock value and so forth. The fine details of crash proof storage requirements need to be worked out.
At a superficial level it would seem that to design a program that provides procedure call abstraction would be a straightforward exercise. Surprisingly this is not so. We have found the problem of the design of the RPC to be extremely intricate. To the best of our ability we have checked that all of the possible normal/abnormal situations eventually map onto the responses of the remote call(...), "get work" and "send result".
{kind=link}