The British Government gave us some money to find out whether computers could be used for typesetting activities, and during the past two years, I think we have found more or less what needs to be done.
I show you now three or four pictures of our original experimental hardware. This shows the input station, as we originally developed it. An IBM Model B input-output writer linked to tape punch with Newcastle-developed logic in the middle.
We modified an IBM Executive typewriter to enable us to have a justified typewriter output, similar to Justowriter, because we thought this was the lowest order of cold type composition acceptable for scientific purposes. We wanted to build a set of hardware to demonstrate that our programs worked without going too elaborate. We wouldn't have built the hardware if we could have bought it, but we couldn't buy it exactly the way we wanted it.
Our next modification was the Monotype paper punch, the standard Monotype paper tower. We had to buy it, but it was at least brand new and guaranteed to work, which it has continued to do. We just fitted a set of solenoids along the bottom and these push on the air valves. It is with this apparatus that we produced the rolls of 31-hole tape that were sent to the printers to cast the type for the Penrose Annual l964 article. Not very long after we got started, I realized what the nub of the whole matter was. The real truth of the situation is this: Printing natural text is governed by statistical rules. Therefore, I give the lie direct to anyone that says that any reader of any combination of human beings can produce a perfect text; I assert that you are going to have errors, and it's just a question of where you place them and what pains you take to get them down to a certain level.
We soon found when we started at Newcastle that we didn't have any statistics. We didn't know where to go because we had no measure to guide us in what we were doing. So, the first thing we did was to pretend to set a lot of texts. This is something you can do very nicely on the computer. You can simulate production without actually going to hot metal. The type of result that we got out says that, if you have here a type of text, a certain type of text, and it is so many Monotype units long -- I hope you will let me use Monotype units as a measure - - there are 18 to the square em (I'd like it to be in millimeters and microns really) -- 603 units long, 405 units line length, 288 units line length, and the lower limit of 3, upper limit of 9, lower limit of 3, upper limit of l5, and so on, gives you the percentage of lines with hyphenations in. You see that if you have a long line length you get very few hyphenations if you only open up the interword spacing to a reasonable or unreasonable limit, as the case may be. (See Figure 1)
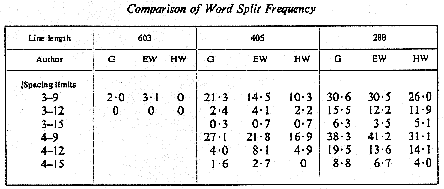
Next we checked the results when using three sorts of texts. The first text we ever analyzed was a passage from Gibbon's "Decline and Fall of the Roman Empire," which is classic prose. We decided we better try Evelyn Waugh and Hugh Williamson just to see if there was any difference. (See Figure 2)
You, in fact, trade wider or narrower word spacing for word breaks. The main thing about our Newcastle program is that we would like to sell to everybody the idea of "minimization," which is simply that you juggle around with the spaces in the paragraph in all the preceding lines in order to get rid of as many word breaks as possible. Why do you want to get rid of word breaks? Because at the time we were playing with it, it looked as though it was an intractable problem to solve, and it looked as though it was an expensive problem because it would probably involve human dictionaries. We hated the idea of a dictionary and have never used one -- we wanted to use a purely logical rule word breaking system.
We guessed we could not succeed completely, but it was worth having tried as a demonstration; and if you do minimize, of course, you can get down to very low incidence of word breaks. If you ask me whether you can minimize at economic rates using existing computers, I can't answer that question. Intuitively I think you can, but I'm not sure. And intuition is a bad substitute, as you know, for real knowledge.
We've done a fair amount of setting at various widths. For instance, when we set the article in Printing Technology we set the first half in 4 to 12 units, and the second half in 4 to 15. We cut the incidence of word breaks in a fairly narrow column -- not as narrow as newspapers, of course -- down from 7 percent to 1.2 percent. This is a significant reduction.
We next examined how many times in certain circumstances the procedure for avoiding splits is successfully invoked, and once you get up to the 12 units as the upper limit on certain line lengths you can invoke the juggling technique very successfully.
At this stage we decided that what we were really after was the truth about how long compositors work. When we decided to set the Penrose Annual article, we first asked them to set a sample piece, and we went through an agonizing period trying to decide what upper limits we ought to set to our spacing. Percy Lund Humphries gave us some statistics for a sample piece of setting for the Penrose Annual, and we tried to adjust the computer setting from 3 to 13 units to simulate the same proportion of lines with wide and narrow spacing as we had had from the handset sample from them.
Unfortunately, and unknown to us, the compositor had had an off day when he was setting us our sample piece. Certainly as we subsequently found the piece we received to measure before we started, was worse than they were able to do in the rest of the Annual.
Anyway, we set 1,872 lines of Penrose Annual with only six word breaks, and subsequently, in another operation, which was reported to the London Conference, we were able to remove five of these word breaks in the 1,872 lines by subtracting minute amounts of letter spacing, which is quite feasible on the Monotype system. We got rid of five of those hyphenations, so we were left with one split for which we had to shift one character. This is the sort of result achievable with a reasonably sized section of text with a line length of 576 Monotype units (M.U.), which is a good book length.
I want to tell you now the sorry story of "Look, No Hands." We had six hyphens and 1,871 full lines, and then the fun started. Without my knowledge the readers got to work on my beautiful text and altered 396 lines, creating a total of 46 new hyphens. That's 11-1/2 percent, which is well above the predicted proportion. There were all sorts of reasons for doing this, but the main reason was that they insisted on writing figures in words, a procedure which doesn't recommend itself very well to mathematicians and engineers. I should have had the house style for this particular thing locked up solid, but I just hadn't.
Now we know better, but this prompts me to say that for machine processing we need a standard style. I would prefer it to be American-British standard engineering English style. I don't go for anything more than that, and when I say style I just don't mean the shape of the letters. I mean where the apostrophe should go, whether there should be space here or there or everywhere, and so on. There are all sorts of house rules that ought to be abolished by statute.
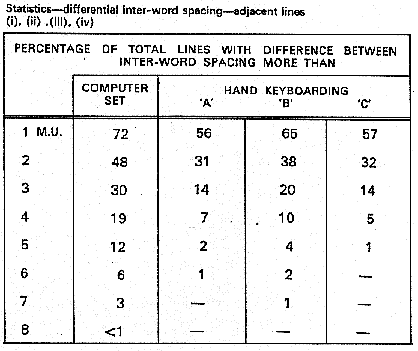
Next, I went shopping with some of our best book printers. They took chunks of galley 576 "monotype" and they wrote down on the right-hand side the wedge settings they had used. Miss Robson put these through the computer, and we took two sorts of statistical distribution. We took the distribution of the spaces, and we took the distribution of the difference between the spacing in adjacent lines, which seemed to me to be a very reasonable thing. Afterwards, Oxford told us that it preferred not to set adjacent lines with more than a difference of four units between the spaces used in the two lines, and, to give the Oxford people their due, they just about got there. We then plotted them, and you will see that because we were using 3 M.U. we gained at one end of the scale but we aren't quite so good as the other people. (See Figure 3)
Of course, printers tell you that they're aiming for an average of about 6 units. They tell you that and they don't do too badly. They're only getting 55 percent, but that's a pretty high proportion with spaces above or below that particular unit.
Here (See Figure 4) you find we get closer setting, but at this end, we've got some rather bad ones. We have about three lines in 100 in which we have a difference of seven units in between spaces. These are relationships which are valid. They've been measured. This is real work. It's not what anybody tells us. It's what they've actually done. They selected the job they gave us. I asked them not to do a special job before they gave us the galleys marked up with the wedge settings. They did take it from their existing production.
Next, these results plotted in a way which I think makes them look significant.
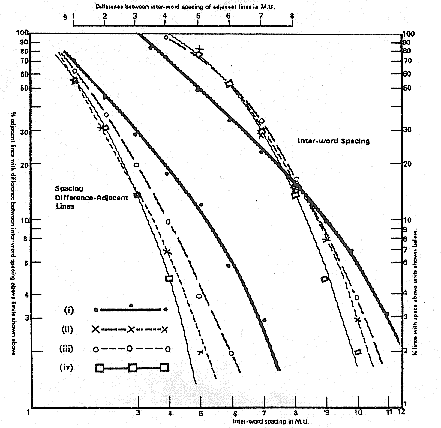
Here (See Figure 5) the thick black lines are the computer set. We're better at one end and worse at the other. We've got a wider spread. And I tell you we've got a wider spread because we were told there was a wider spread on the specimen we did before we set the one that we measured here. We could have closed the computer limits down. You can have a range of solutions according to either your taste or your pocket. This is what the computer does for you. It says "specify and we will charge you."
These are the adjacent spaces. We do all right at this end, and we widen out at this end. It's a semi-logarithmic scale so it's rather difficult to picture exactly what that means. It's a very difficult thing to show you because nobody can really tell you how significant one or two lines may be.
I have some setting here which is from a very good book house in England. It has just come to me because I thought I'd do a little bit more. I wasn't entirely satisfied with the four samples originally plotted. This is actually a legal document, and I'm horrified to find (I'm sure they will be, too) that there is one line with 17 units of space in it, one with 16, three with l4, and so on down the scale. And there are two lines with a difference of more than 9 units in between the adjacent lines, and there is one with more than 10.
This is a good book house doing good work, but they are way off the beam in telling us that we must keep to an upper limit of 9 and that we mustn't have a difference of more than 4 M.U. between adjacent lines. They are in fact doing just what we have to do with the computer. They're meeting a natural system in a statistical way. If they are confined as we are to not being able to alter the text, which is the trick you must engage in if you want to avoid these natural laws, then they are bound to come up with the same sort of result as we are bound to come up with unless they've got a much wider range of hyphenation available in their "program" than we have. You could say they have it in their heads, but this isn't true because when you tackle them on hyphenation, you meet a very similar situation.
You can imagine that by this time I was getting very skeptical and I thought to myself: "I'm not going to argue with them. I'm going to take an Oxford book and two Cambridge books and I'm going to take all the splits I can find in these books, sort them, discard the duplicates and double spellings, and then I am going to see how well our computer program does on these."
We took these words and also random selections from the U.S. Government Printing Manual, Part II (which has a lot of big words, as you know, very difficult ones), and we put them into the computer, and we marked them all with the permitted Webster word-break positions.
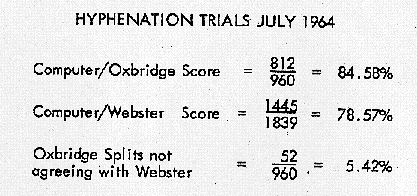
Having done this, we did the scores and found that our computer program, which is a pure logic program, doesn't do anything like as well on the Webster score, which does at least mean that Dr. Eve, when he devised the logical system, was meeting an English idea of what hyphenation should be and not a German-American one.
The interesting thing is the difference between the two criteria, which is only 5 percent; so that's all that is separating us, gentlemen, over where words ought to be hyphenated. (See Figure 6)
But I would add that that 5 percent might just as well be 55 percent for the gap that is met when you talk to English publishing houses about American hyphenation or, I presume vice versa.
I have now taken these sets of words and submitted them to five houses and asked them to give them to their head and deputy head readers with the special instruction that they will get them to tick or cross the hyphenations which the computer and Oxbridge give whether they in fact approve of these real hyphenations, and we'll score them up like that.
I also submitted the words to five other hyphenation programs: two German, one French, and two English. I got the results of one German program, and I think they will interest you. The German program splits vis-a-vis Oxbridge agreed settings, scores 83 percent. The German program gets 85 percent of the Webster right. That seems to suggest that there is an affinity between Webster and the Germans. This is for the word-break positions in Webster's New Collegiate. I expect to get some of these national variations showing. I think this may tell us just how much a generalized hyphenation program is possible. Certainly this thing about Webster and the German program is an interesting point. I can see there must be reasons for it which I must talk to the linguistics people about. I really did it in a spirit of inquiry rather than of real understanding of what I was going to get at.
I will read you one or two of the remarks of the manager of the plant. He says, and I'm quoting him because this is real experience from a real hard-headed man:
"In general we agree with Oxbridge divisions for English work because we were brought up on them. We also print American work, and for this we try to apply the Webster rules which, broadly speaking, are the same as the U.S. Government list. The important thing is not to leave in doubt what is following and not to suggest the wrong word, and at the same time not to prolong the reading of a word by turning over an insignificant part."
That is a twist to this business of turning over a small part that I haven't heard before. By the way, we do not turn over two letters, although I would have liked to turn over "ed" and "ly" as a general rule.
"We have always held the opinion that a national body should be set up comprising representatives of all concerned (and now computer programs) to furnish a rational set of rules for division of words. Only then could various authorities be made to accept a universal English system. Even then there seems to be a gulf between English and American usage that those rules would not embrace both sides of the Atlantic."
"Many publishers insist upon close and even line spacing. Obviously, the best divisions cannot, then, always be made. More often than not inferior divisions are set and the cost of overrunning prohibits the reader from altering what has been set. Nowadays printers' readers can usually alter only those divisions that have been set that are regarded as inexcusable."
"Our only in-plant instruction with regard to divisions because of close and even spacing is to tell operators, readers, and compositors to use any suitable division but to avoid using divisions that are obviously bad."
This is the only division which you throw out of the computer system. You can't have degrees of acceptability; its's either in or it's out, because at some time or other that word is going to occur in a situation where it has got to either go in or out. It's the law of the Medes and Persians. There aren't any grays in word breaks; they're either good or bad.
"Thus the best divisions are often not set, but usually those that are set pass."
Here he has really got to the crux of the matter. He has now come through to the end of the long dark tunnel himself to a full realization of just how his processes work inside his own factory.
"Some divisions in the list we have agreed are just possible, but not preferred. They could be used in extremely difficult circumstances. These will occur in computer setting as well as in the traditional method, and it will be essential that the programmer know the difference between an indefensible division and a just possible one. Some publishers are much more fussy with regard to division than others. Could they be made to toe the line? It is probably that only an economic inducement would make them do so."
That tells you very roughly what we've been up to and how we probably will go on trying to collect some natural true information about how human beings are working in this particular field, so we can at least shape up our computer programs on the basis of a reasonable assessment of what they think they want.
That's the end of the story, I think. All I would say to you is that we have become very humble over the years. As a team we realize we don't know a lot of things. We also get a little consoled because we have realized that the printers don't know everything either. The right combination, of course, is for everybody to cooperate, and that's what we re going to try to do in the future.
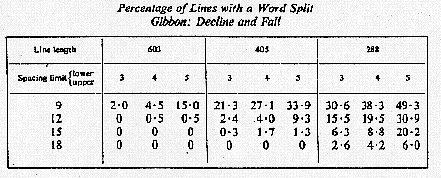{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}